.png)
 há 8 meses
9
há 8 meses
9
Saudações. Nesse artigo vamos explorar um item vital para a Internet: um componente HTTP chamado proxy-reverso, suas implementações, principais softwares e exemplos práticos.
Abordaremos os softwares: Nginx, Nginx Proxy Manager, Lighttpd, Traefik, Caddy e Squid.
Pre-requisitos pra praticar os exemplos:
- Servidor, VM ou VPS com Linux Debian 12 e Docker;
- O Linux deve possuir IP público (IPv4) e IPv6 global;
- Ter pelo menos 1 domínio (DNS) para os testes de URLs (vou usar exemplo.com.br e você muda para o seu);
- Comando “curl” para os testes;
Instale os programas básicos que vamos usar:
Bash
# Instalar utilitarios de sistema apt-get -y install psmisc apt-get -y install iproute2 apt-get -y install net-tools # Instalar linguagens utilizadas nos exemplos apt-get -y install python3 # Instalar programas básicos de HTTP apt-get -y install curl apt-get -y install wget apt-get -y install lighttpd apt-get -y install nginx apt-get -y install apache2-tools # Parar sistemas que se auto-iniciaram nas instalacoes acima: systemctl stop nginx systemctl disable nginx systemctl stop lighttpd systemctl disable lighttpd;1 – O básico sobre o protocolo HTTP
O protocolo HTTP é de longe o protocolo mais simples e mais usado na Internet. Ele foi concebido para ser uma troca simples de arquivos e acabou dominando a forma de usar a Internet.
O HTTP é uma arquitetura cliente-servidor. O servidor é um software passivo, ele apenas entra em operação quando o cliente envia uma requisição para ele. As requisições e respostas seguem o mesmo formato de texto: tipo (primeira linha) + cabeçalhos (1 por linha) + linha em branco + conteúdo (opcional).
Regras básicas de comunicação entre o cliente e o servidor:
- A primeira linha da requisição deve ser o método, lista de todos os métodos: GET, POST, PUT, DELETE, PATCH, HEAD, OPTIONS, TRACE;
- A primeira linha da resposta deve ser o protocolo em uso e o código de retorno;
- As linhas seguintes devem ser pares: nome do parâmetro de cabeçalho, “:” (dois-pontos) e o valor;
- Cada linha do cabeçalho deve ser finalizada com uma quebra de linha composta pelos caracteres CR+LR (CR = “\r” = Carriage Return, código decimal 13 da tabela ASCII, LF = “\n” = Line Feed código decimal 10 da tabela ASCII);
- Quando os parâmetros de cabeçalho se encerrarem, uma linha em branco deve ser inserida, ou seja, CR+LF do cabeçalho anterior e CR+LF de uma linha vazia, assim a combinação CR+LF+CR+LF marca o fim do cabeçalho.
- Apos a linha em branco, opcionalmente, pode ser enviado mais bytes, esse é o conteúdo anexado na requisição (upload ou envio de formulário) ou, na resposta (o documento solicitado);
Exemplo do requisição:
Bash
# Requisicao ao google: curl -v https://www.google.com/robots.txt # Retorno do comando acima: # Estabelecendo conexao TCP... # Estabelecendo canal TLS... # Requesicao enviada ao servidor: GET /robots.txt HTTP/2 Host: www.google.com User-Agent: curl/8.7.1 Accept: */* (linha em branco, fim da mensagem) # Resposta do servidor ao cliente: HTTP/2 200 accept-ranges: bytes vary: Accept-Encoding content-type: text/plain content-length: 9340 date: Thu, 23 Jan 2025 14:52:05 GMT expires: Thu, 23 Jan 2025 14:52:05 GMT cache-control: private, max-age=0 last-modified: Thu, 09 Jan 2025 17:00:00 GMT server: sffe (linha em branco) [texto da resposta, muito longo pra colar aqui!]A resposta segue o mesmo padrão da requisição, no entanto, a primeira linha informa o protocolo (HTTP) e versão, seguido de um espaço e o código de retorno. Códigos:
- 1xx – resposta informativa (não é usada)
- 2xx – resposta conclusiva – o que você pediu foi atendido
- 3xx – resposta dispersa – você deve ir a outro lugar (nova URL)
- 4xx – resposta negativa – o pedido não pode ser atendido, arquivo não existe ou restrições foram aplicadas para impedir o envio;
- 5xx – resposta de pane – alguma coisa deu errado e o servidor HTTP não consegue processar até o final seu pedido (falha na cadeia de softwares no lado servidor);
Viu como é simples? Os outros detalhes são corriqueiros e simples de aprender.
Vou apresentar os cabeçalhos mais comuns, marcando com [S] os cabeçalhos enviados do servidor para o cliente, [R] nos cabeçalhos que constam na requisição, e [*] para cabeçalhos usados em ambas as operações;
- [R] GET, POST, DELETE, HEAD: o tipo de pedido que o cliente deseja fazer, é a primeira linha da requisição e não é separado por “:”, é seguido do PATH (caminho, exemplo: /chat, /clientes/lista, /client/info?id=1234). Se o caracter “?” estiver presente no PATH, tudo depois do “?” se chama “query” (exemplo: ?id=1234) e costuma ser usado para orientar os detalhes do pedido quando o cliente não deseja submeter isso no corpo;
- GET: o cliente deseja obter um conteúdo;
- POST: o cliente deseja submeter uma informação que irá determinar como o servidor irá responder, usado para criar ou atualizar o lado servidor;
- HEAD: semelhante ao método GET, mas visa obter apenas o cabeçalho da resposta, o servidor não deverá enviar conteúdo;
- DELETE: o cliente deseja remover algum arquivo ou objeto do servidor;
- [S] Server: o servidor HTTP informa ao cliente qual software está processando a requisição (normalmente é o nome do próprio software servidor HTTP);
- [R] User-Agent: nome do software utilizado pelo cliente (nome do navegador ou APP);
- [R] Host: nome de DNS do site desejado, ou IP do site desejado (ex.: google.com, 200.160.2.3);
- [*] – Content-Type: tipo de conteúdo que está sendo negociado. O cliente pode pedir um tipo, mas o servidor pode mandar outro. Tipos mais comuns:
- text/html – páginas HTML;
- text/plain – texto puro;
- text/css – texto com código CSS de personalização das páginas HTML;
- text/csv – texto de planilhas CSV;
- text/javascript – texto com código javascript (software da página);
- image/jpeg – Imagem;
- image/png – Imagem;
- application/json – texto de dados estruturados JSON;
- application/octet-stream – tipo indefinido ou binário detectado (download);
- [*] Content-Length: quando presente, informa qual o tamanho do documento presente no corpo da requisição ou no corpo da resposta. Costuma ser omitido mesmo quando há conteúdo presente;
- [S] Date: data universal de criação do conteúdo;
- [S] Expires: informa a data universal limite de vida do conteúdo, é usado pelo navegador para saber por quanto tempo o arquivo/objeto pode ser mantido no cache do cliente;
- [S] Cache-Control: configurações para que o objeto seja armazenado em cache;
- [S] Location: nova URL a ser usada (redirecionamento), acontece em respostas com código 3xx pois o servidor moveu o conteúdo para outra URL;
Quando você abre um navegador para acessar um site (https://google.com por exemplo), seu navegador envia um “Get /, Host google.com” e recebe “HTTP/2 200, Content-Type: text/html” seguido do texto HTML da página inicial do Google.
Partes de uma URL:
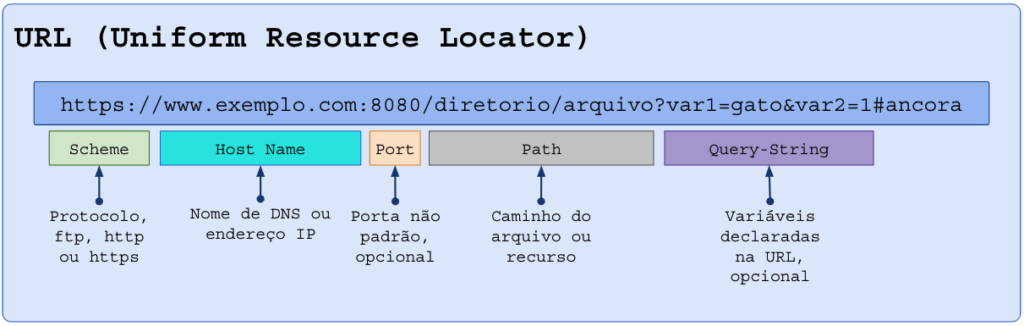
Se a porta (“port”) não for informada, o software cliente presumirá:
- Para o esquema (“scheme”) http, porta 80;
- Para o esquema (“scheme”) https, porta 443;
2 – O servidor HTTP
O servidor HTTP é o software que será executado abrindo alguma porta TCP para escutar os pedidos (requisições) dos clientes, normalmente a porta 80 (HTTP) ou 443 (HTTP+TLS).
Antigamente haviam poucos softwares para isso, dada a simplicidade da função, o Apache dominou por muito tempo.
Eu particularmente gosto muito do Lighttpd e do Nginx para servidores simples e pontuais.
A função do servidor HTTP é mapear o site “www.seusite.com” (DNS apontando para o IP, exemplo: IPv4=45.255.128.2 e IPv6=2804:CAF9:1234::2) em uma pasta do servidor, por exemplo, /var/www/htdocs/.
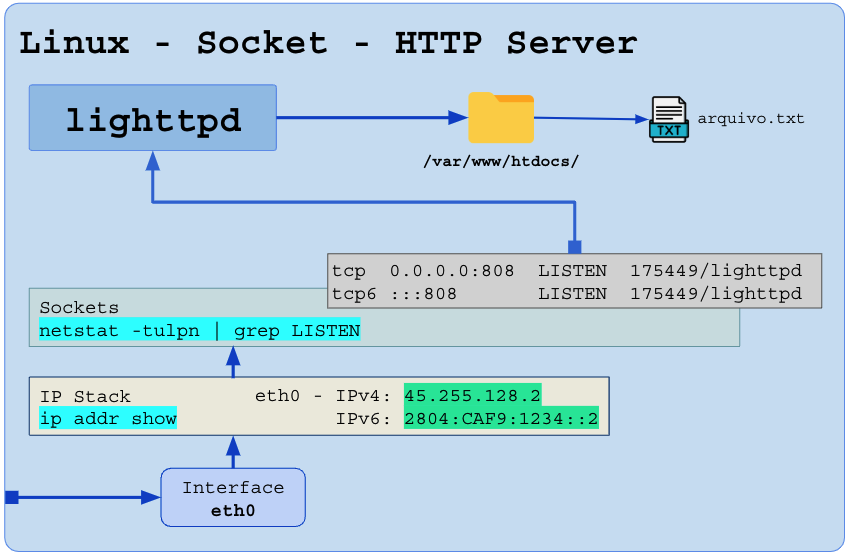
Ao enviar um pedido “GET /arquivo.txt“, o servidor vai no caminho /var/www/htdocs/arquivo.txt, lê o arquivo, coloca ele no corpo da mensagem que será iniciada assim “HTTP/1 200“. Se o arquivo não existisse, a resposta seria “HTTP/1 404” sem nada no corpo da resposta.
Praticando o exemplo acima:
Bash
# Diretorio de base: mkdir -p /var/www/htdocs # Arquivos de exemplos: echo "O rato roeu a roupa do rei de roma" > /var/www/htdocs/arquivo.txt echo '{ "name": "Patolino", age: "6" }' > /var/www/htdocs/data1.json echo -n "1" > /var/www/htdocs/1byte.txt # Configuracao minima do lighttpd: ( echo 'server.port = 808' echo 'server.document-root = "/var/www/htdocs"' ) > /etc/lighttpd/test.conf # Rodar o servidor HTTP com lighttpd para servidor arquivos em uma pasta: killall lighttpd lighttpd -f /etc/lighttpd/test.conf # Testando funcionamento (127.0.0.1 é o ip de loopback, se chama localhost) curl -v http://localhost:808/arquivo.txt #* Trying 127.0.0.1:80... #* Connected to localhost (127.0.0.1) port 80 (#0) # Requisicao: #> GET /arquivo.txt HTTP/1.1 #> Host: localhost #> User-Agent: curl/7.88.1 #> Accept: */* #> # Resposta: #< HTTP/1.1 200 OK #< Content-Type: application/octet-stream #< Content-Length: 35 #< Accept-Ranges: bytes #< Date: Fri, 24 Jan 2025 15:44:03 GMT #< Server: lighttpd/1.4.69 #< #O rato roeu a roupa do rei de roma #* Connection #0 to host localhost left intact # Parar o lighttpd de teste: killall lighttpdO servidor HTTP faz a deteção automática do tipo do arquivo, e responde o tipo MIME no cabeçalho Content-Type, há um tipo padrão informado na configuração e há o arquivo mime com a extensão do arquivo e o tipo (.txt = text/plain, .html = text/html, .css = text/css, …). Na ausência do arquivo MIME o tipo padrão costuma ser “text/html” ou “application/octet-stream”.
Scripts no lado servidor: CGI e FastCGI
Uma tecnologia vital foi a implementação do CGI e FastCGI. Esse recurso permite ao servidor HTTP vincular um caminho da URL a um programa que será executado para produzir o conteúdo. O conteúdo é produzido em tempo real de acordo com os detalhes do pedido, e assim surgiu o PHP e a Web 2.0 (sites de conteúdo dinâmico e interativo).
Observe esta configuração do Lighttpd:
Ela informa que toda URL terminada com “.php” deve ser enviada ao SOCKET UNIX do PHP (php-fpm). O php-fpm recebe uma mensagem do servidor HTTP contendo o arquivo solicitado e as variáveis HTTP (Query-String), executará o script PHP, e o retorno do script é devolvido ao servidor HTTP para ser servido ao cliente.
Scripts que rodam como HTTP Server
Outra evolução no uso de HTTP foi que as linguagens de programação passaram a implementar a abertura da porta TCP e a interpretarem diretamente a requisição. Python, NodeJS e Ruby são os mais comuns.
Com essa recurso, seu programa escrito em Python pode abrir a porta TCP, receber os pedidos em HTTP, fazer o “roteamento” de cada pedido para uma função interna.
Algoritmo simples para processar HTTP (implementação de API simples, gravar em /root/py-server-api-ex01.py):
- Abrir a porta TCP 820 como servidor HTTP;
- Criar as rotas para cada tipo de pedido:
- Quando for solicitado “Get /”, acionar a função home_page();
- Um “GET /client/list” aciona a função clients_list();
- Um “GET /client/123” aciona a função client_get(123);
- Um “POST /client/123/disable” aciona a função client_disable(123);
Python
from http.server import HTTPServer, BaseHTTPRequestHandler import re # Funções para tratar as rotas def home_page(): return {"status": "1", "message": "Welcome to the home page!"} def clients_list(): return {"status": "1", "clients": ["Client A", "Client B", "Client C"]} def client_get(client_id): return {"status": "1", "id": client_id, "name": f"Client {client_id}"} def client_disable(client_id): return {"status": "1", "id": client_id, "msg": f"Client {client_id} disabled"} # Manipulador HTTP class MyRequestHandler(BaseHTTPRequestHandler): def do_GET(self): # Rota "/" if self.path == "/": response = home_page() # Rota "/client/list" elif self.path == "/client/list": response = clients_list() # Rota "/client/<id>" elif match := re.match(r"^/client/(\d+)$", self.path): client_id = int(match.group(1)) response = client_get(client_id) # Rota "/client/<id>/desativar" elif match := re.match(r"^/client/(\d+)/disable$", self.path): client_id = int(match.group(1)) response = client_disable(client_id) else: self.send_response(404) self.end_headers() self.wfile.write(b'{"status": "error", "message": "Not Found"}') return # Responder com sucesso self.send_response(200) self.send_header("Content-type", "application/json") self.end_headers() self.wfile.write(bytes(str(response), "utf-8")) # Iniciar o servidor HTTP def run_server(port=820): server_address = ("", port) httpd = HTTPServer(server_address, MyRequestHandler) print(f"Starting server on port {port}...") httpd.serve_forever() if __name__ == "__main__": run_server(820)Rodando script Python e consultando nossa API de teste:
Bash
# Rodar servidor API python: python3 /root/py-server-api-ex01.py \ 1>/var/log/pysrv-ex01.log \ 2>/var/log/pysrv-ex01.log & # Chmando API: curl -v http://localhost:820/client/list #* Trying 127.0.0.1:820... #* Connected to localhost (127.0.0.1) port 820 (#0) # Requisicao: #> GET /client/list HTTP/1.1 #> Host: localhost:820 #> User-Agent: curl/7.88.1 #> Accept: */* #> # Resposta: #* HTTP 1.0, assume close after body #< HTTP/1.0 200 OK #< Server: BaseHTTP/0.6 Python/3.11.2 #< Date: Fri, 24 Jan 2025 16:11:37 GMT #< Content-type: application/json #< #* Closing connection 0 # Conteudo retornado: #{'status': '1', 'clients': ['Client A', 'Client B', 'Client C']}Evolução dos ambientes
Algumas coisas aconteceram depois de 2010 que tornaram as coisas mais complexas:
- A invenção do Docker e os ambientes com container;
- A migração em massa da internet HTTP para HTTP+SSL/TLS para proteger as informações como padrão de segurança obrigatório;
- Os navegadores modernos (Firefox, Safari, Google Chrome) passaram a exigir configurações de segurança mais elevadas, forçando HTTPs como padrão;
- A necessidade de balancear a carga de muitas requisições em vários servidores (load-balance), bem como o monitoramento em tempo real de quais servidores internos estão disponíveis para receber esses encaminhamentos;
- Os sistemas se tornaram mais heterogêneos, sites passaram a contar com muitas tecnologias agregadas, frameworks, APIs, web-sockets, anti-bots, atendimento diferenciado por geolocalização (GEOIP DNS Split-Horizon);
- A migração gradual para o IPv6, enquanto mantem o legado IPv4 em produção;
- As metodologias de teste e publicação de código em produção (atualizar um site em partes sem quebrar o funcionamento do sistema);
- A migração em massa para HTTP, WebSockets e JSON como método padrão de interoperabilidade;
- Softwares antigos foram substituídos por softwares mais avançados e flexíveis, como NGINX, Lighttpd, Traefik, Caddy, entre outros, mais focados em recursos de proxy-reverso;
- A implementação de TLS foi automatizada por meio do protocolo ACME (Automated Certificate Management Environment), o Let’s Encrypt surgiu permitindo que todo site obtesse um certificado assinado e reconhecido mundialmente sem custo;
A lista acima vai crescendo. Fica impraticável manter um software “monólito” que faça isso tudo.
É melhor deixar um software cuidando de todas elas, e seu aplicativo ou software fica apenas com o processamento de dados que serão trocados.
3 – O proxy-reverso
Um bom exemplo para entender a necessidade de um proxy-reverso é seguinte caso:
- Temos um site de vendas online, ex.: CompreFlix – compreflix.com;
- Todos os acessos ao diretório (path) /data deve ser responsabilidade do software de CRM;
- Todos os acessos ao diretório /pay devem ser responsabilidade do software de loja virtual;
- Todos os acessos a /support deve ser processada pelo sistema de Help-Desk;
O software que abriu a porta TCP (80 e 443) receberá todas as requisições, mas ele deve rotear a requisição (encaminhar de forma transparente) para diferentes sub-sistemas que estão rodando em outros softwares.
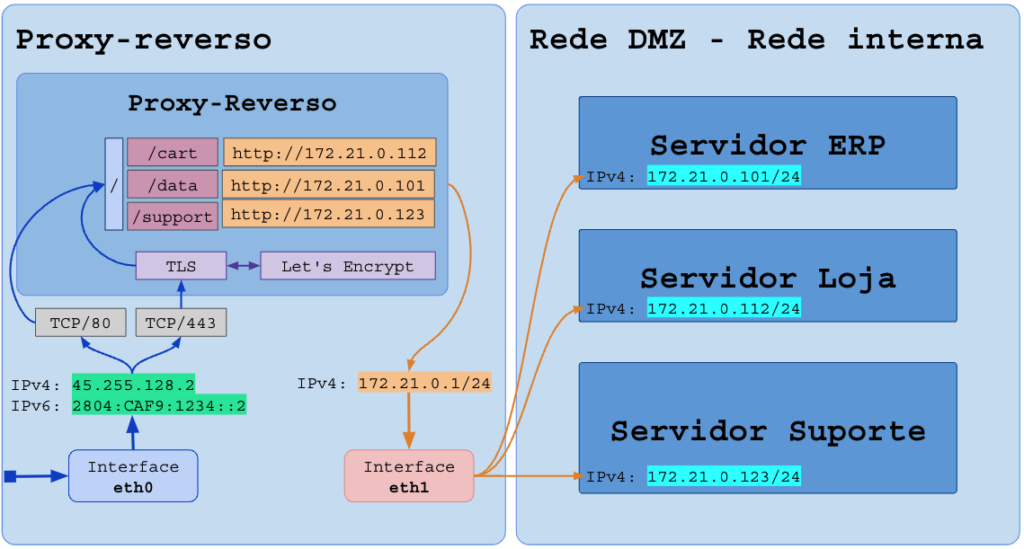
Essa é a função do proxy-reverso.
O proxy-reverso pode, e deve, ser responsável por gerir o certificado de criptografia, atender nas portas 80 (HTTP), 443 (HTTPs) e demais portas necessárias para gestão (8080 por exemplo) e enviar as requisições programadas para os servidores internos.
4 – Proxy Reverso em ambiente Docker
Embora seja comum rodar o proxy-reverso direto no ambiente do servidor (HOST), isso tem como efeito colateral a dificuldade de criar os apontamentos quando as aplicações HTTP internas estão em containers Docker. Você precisaria fixar o IP de todas elas para ter uma configuração confiável, e perderia na flexibilidade (escala, balanceamento, etc…).
A opção mais encorajada e comum é rodar o proxy-reverso em Docker, em uma rede (docker network) personalizada (“network_public”, “apps”, “br-ias”, etc..), visto que na rede nativa do docker o mapeamento automático de nomes e containers não funciona.
Cuidado: o Docker redireciona portas por meio de firewall do Linux (camada prerouting do netfilter) e isso faz com que a porta redirecionada no Docker e mapeada para um container vença a porta do software que você rodou no HOST.
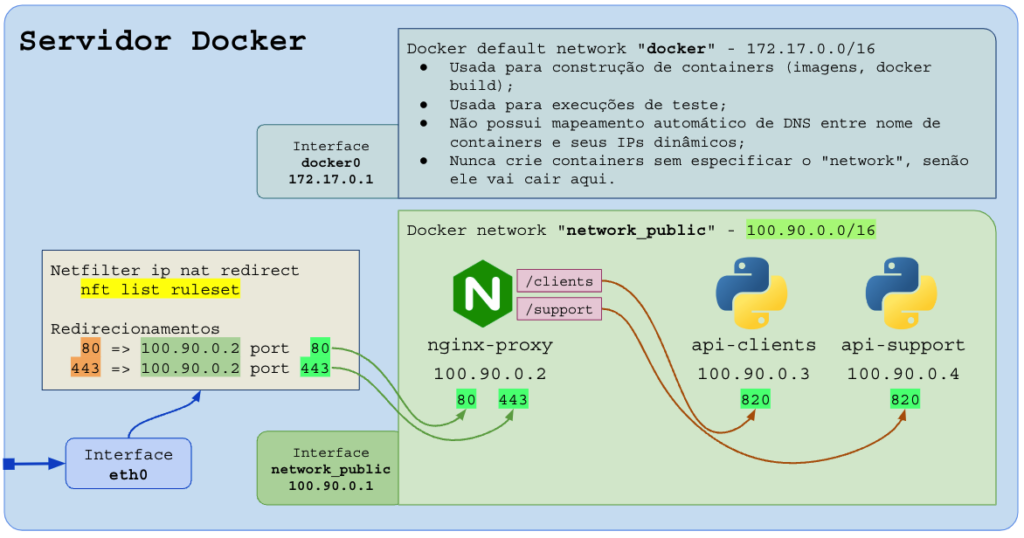
No exemplo acima, podemos ter o site online (exemplo.com.br) e cada diretório (/clients, /support) será entregue ao container responsável.
A importância de criar uma “docker network”, acima nomeada como “network_public” para colocar todos os containers juntos do proxy-reverso é o recurso de mapeamento de nomes no DNS dos containers. O proxy pode usar “http://api-clients” que a camada de DNS do container mapeará automaticamente para o IP que foi atribuído ao container com o nome “api-clients”.
Para tornar seus sites, APPs e APIs compatíveis com IPv6, basta que o servidor (HOST) tenha IPv6 global e que você entregue um docker network com IPv6 (privado, local). Dessa forma as conexões de entrada em IPv4 e IPv6 serão entregues ao seu proxy-reverso, mas o proxy reverso pode entregar as requisições HTTP para os containers e servidores internos que não possuem IPv6 (somente IPv4):
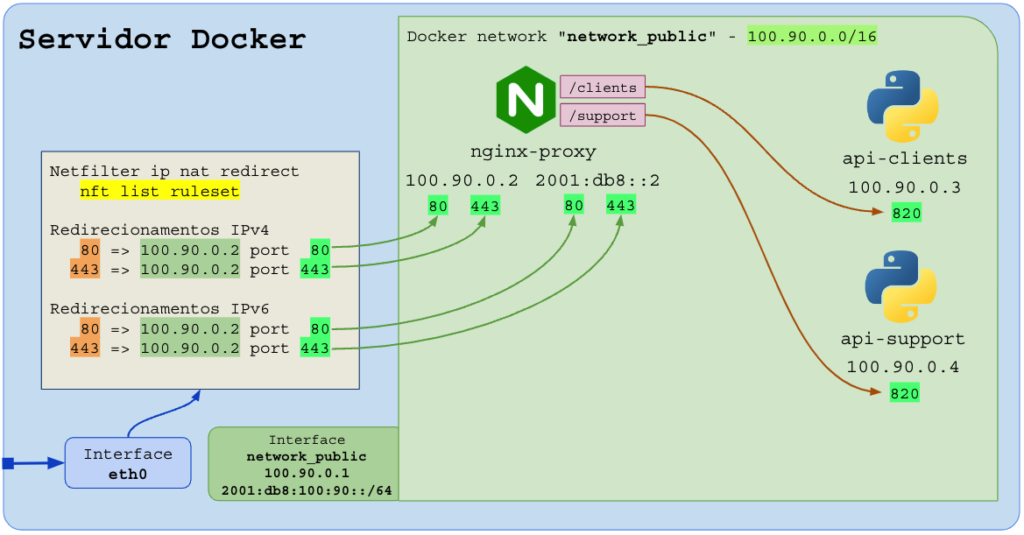
Exemplo de criação da rede “network_public” no Docker, IPv4-Only e IPv4+IPv6:
Bash
# Criar rede para APPs atendidos por proxy-reverso # - No linux, a interface se chamará br-net-public # - No docker, a rede se chamara network_public # - o ICC=true ativa a comunicacao entre containers # - Colocar MTU em 9000 para acelerar a comunicação entre containers # - As opcoes '-o' podem ser removidas, se desejar # Somente IPv4: docker network create \ -d bridge \ -o "com.docker.network.bridge.name"="br-net-public" \ -o "com.docker.network.bridge.enable_icc"="true" \ -o "com.docker.network.driver.mtu"="9000" \ --subnet 100.90.0.0/16 \ network_public # Dual-Stack - IPv4 + IPv6: docker network create \ -d bridge \ -o "com.docker.network.bridge.name"="br-net-public" \ -o "com.docker.network.bridge.enable_icc"="true" \ -o "com.docker.network.driver.mtu"="9000" \ --subnet 100.90.0.0/16 \ --ipv6 --subnet=2001:db8:100:90::/64 \ network_public # Comandos para verificar a rede no Linux (apos criar com os comandos acima): # ip addr show dev br-net-public # ip neigh show dev br-net-public # brctl show br-net-public # tcpdump -pnevas0 -i brctl show br-net-public5 – Nginx Proxy Manager (NPM)
O NPM – Nginx Proxy Manager é um dos melhores. Baseado em NGINX e com plugins que tornam a configuração e a automação muito simples.
Pontos fortes:
- Interface muito amigável e fácil de operar;
- Configura automaticamente os certificados TLS usando provedores gratuitos (ACME – Let’s Encrypt);
- Possui recursos de segurança para restringir acessos a URLs;
- Agrupa sites em certificados wildcard (certificado *.exemplo.com.br pode ser usado em vários containers, permitindo uso de wildcard de DNS);
Pontos fracos:
- Difícil de automatizar para que containers criados com “labels” sejam automaticamente mapeados no NPM sem necessidade de criação manual do mapeamento da URL;
Criar container NPM:
Bash
# Criar container NPM na rede network_public # npm = nginx-proxy-manager # Criar diretorio para armazenar no HOST os dados produzidos dentro do container mkdir -p /storage/npm-app/data mkdir -p /storage/npm-app/letsencrypt # Remover container caso exista: docker rm -f npm-app # Remover imagem atual para forçar reconstrução com imagem atualizada: docker rmi jc21/nginx-proxy-manager:latest # Baixar imagem nova (opcional, o comando docker run abaixo ja faz isso) docker pull jc21/nginx-proxy-manager:latest # Criar container: # - nome: npm-app # - portas: # 80 = HTTP # 81 = Gerencia # 443 = HTTPs (HTTP+TLS) # - pastas: # /storage/npm-app/data mapeada em /data dentro do container # /storage/npm-app/letsencrypt mapeada em /etc/letsencrypt dentro do container # # - banco de dados de login e mapeamentos salvos no arquivo # /data/database.sqlite dentro do container, que será mapeado no caminho # /storage/npm-app/data/database.sqlite # docker run \ -d --restart=unless-stopped \ \ --name npm-app -h npm-app.intranet.br \ --network network_public \ \ -p 80:80 \ -p 81:81 \ -p 443:443 \ \ -e DB_SQLITE_FILE=/data/database.sqlite \ \ -v /storage/npm-app/data:/data \ -v /storage/npm-app/letsencrypt:/etc/letsencrypt \ \ jc21/nginx-proxy-manager:latest # Acesse......: http://ip-do-servidor:81/ # Login padrao: admin@example.com / changeme # Nota: # - sempre faça backup do /storage do HOST # - destruir e recriar o container do NPM nao deve ser problema # pois os dados sempre ficam fora do container e serão os mesmos # toda vez que você roda-loTela de login inicial (porta TCP 81), usuário admin@example.com senha changeme:

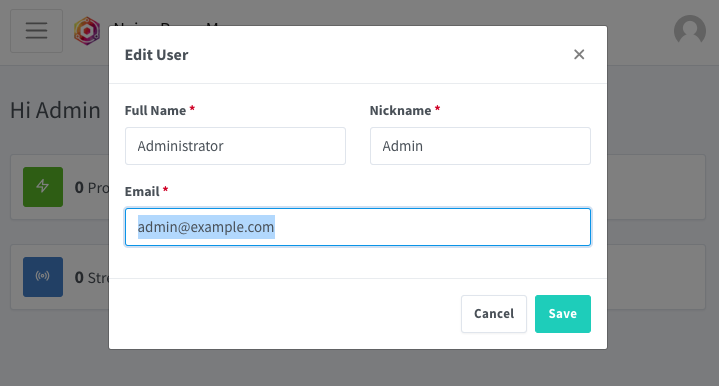
Altere o email no primeiro login (o email será o novo usuário para autenticação):
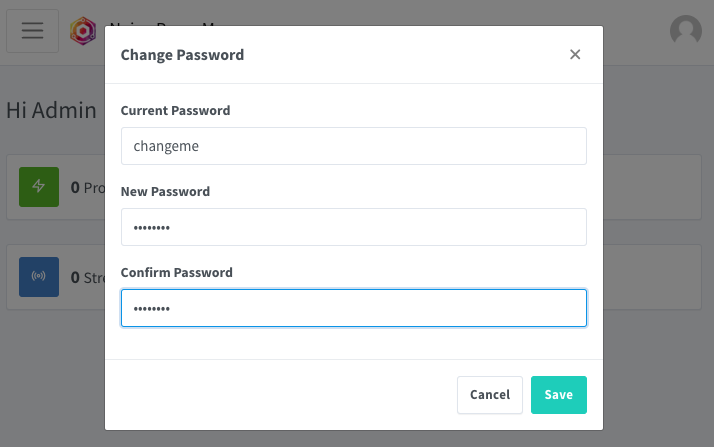
Altere a senha (senha padrão changeme):
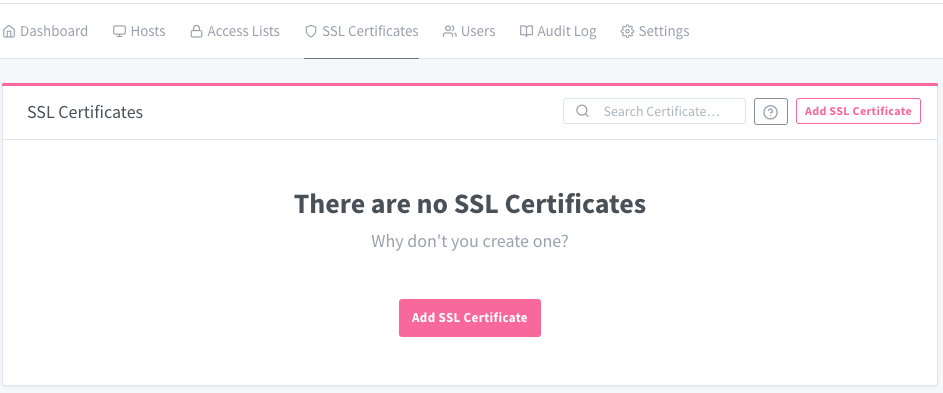
O primeiro passo no NPM é cadastrar os nomes de DNS (FQDN) que serão usados no menu de certificados “SSL Certificates“. Você deve cadastrar 1 nome de cada vez, evite agregar vários nomes juntos (não funciona todas as vezes por restrições no provedor ACME / Let’sEncrypt).
Troque “exemplo.com.br” pelo seu domínio real que aponta para o IPv4/IPv6 do seu servidor rodando NPM. Registre em seguida o nome “www.exemplo.com.br“.
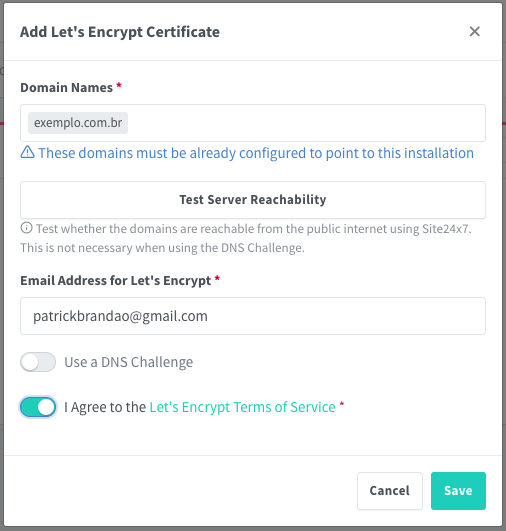
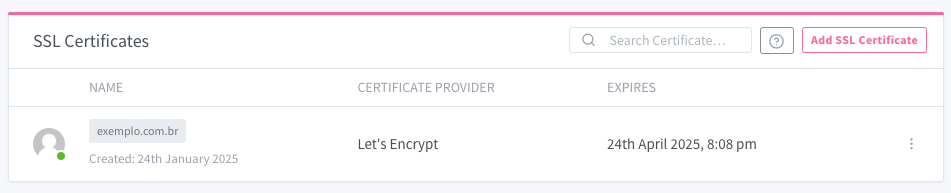
Certificado registrado e funcional via Let’s Encrypt. O NPM renovará o certificado automaticamente antes do vencimento. Você não precisa se preocupar nunca mais!
Precisamos de um container para hospedar o site em si, mesmo que de exemplo (hello-world), vamos fazer isso com um container lighttpd para servidor uma página inicial de exemplo:
Bash
# Criar a pasta no HOST: mkdir -p /storage/hello-world-home echo 'Ola mundo, deu certo' > /storage/hello-world-home/index.html # Rodar o container chamado hello-world-home # - Observe que não há porta mapeada, esse container é 100% privado docker run -d \ -d --restart=unless-stopped \ --name hello-world-home -h hello-world-home.intranet.br \ --network network_public \ \ -v /storage/hello-world-home:/var/www/html:ro \ \ rtsp/lighttpdVamos criar um redirecionamento no NPM de tudo que for para o “exemplo.com.br” para o container “hello-world-home” porta 80. Vá no menu “Hosts” -> “Proxy Hosts“:
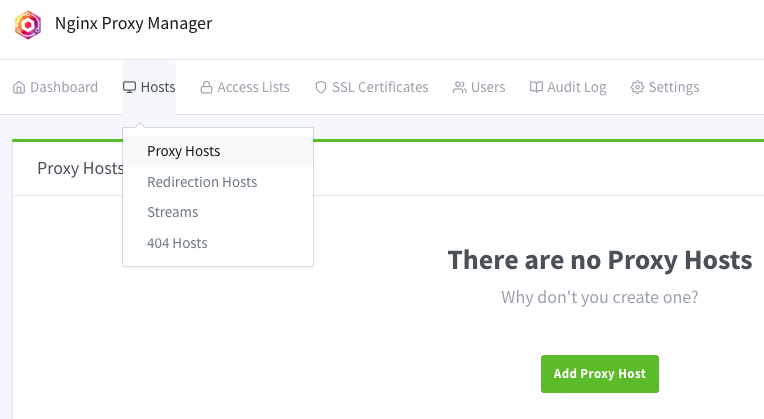
Adicione o nome de DNS (exemplo.com.br) em “Domain Names” (pode ser mais de um). NÃO clique em “SAVE”, vá em “SSL” em seguida.
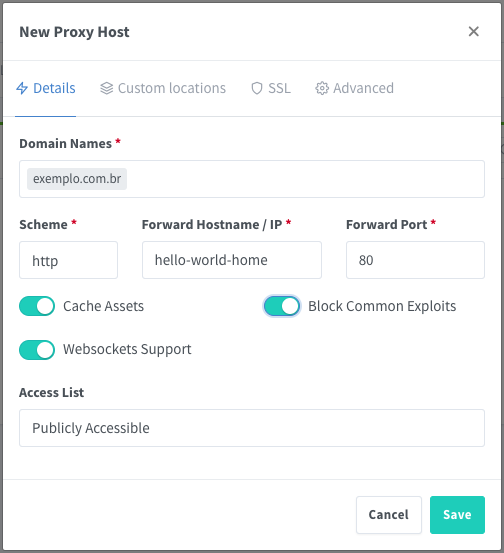
Selecione o certificado registrado com o mesmo nome configurado:
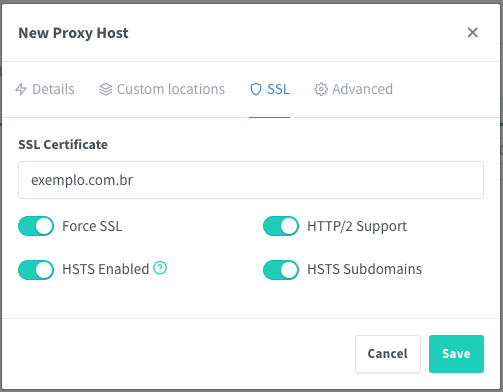
Salve clicando em “SAVE”. O apontamento foi realizado com sucesso. Testando:
Bash
# Teste: curl -v https://exemplo.com.br/ #* Using Stream ID: 1 (easy handle 0x5611e3deace0) #> GET / HTTP/2 #> Host: exemplo.com.br #> user-agent: curl/7.88.1 #> accept: */* #> #< HTTP/2 200 #< server: openresty #< date: Fri, 24 Jan 2025 22:20:52 GMT #< content-type: text/html #< content-length: 21 #< etag: "2574584986" #< last-modified: Fri, 24 Jan 2025 21:20:35 GMT #< accept-ranges: bytes #< strict-transport-security: max-age=63072000;includeSubDomains; preload #< x-served-by: exemplo.com.br #< #Ola mundo, deu certoCom o domínio inteiro recebido, agora vamos redirecionar uma pasta específica do site para outro container, vamos criar um container exemplo de API:
Bash
# Criar a pasta no HOST: mkdir -p /storage/hello-world-api echo '{ "nome": "Patolino", "age": "6" }' > /storage/hello-world-api/index.json # Rodar o container chamado hello-world-home # - Observe que não há porta mapeada, esse container é 100% privado docker run -d \ -d --restart=unless-stopped \ --name hello-world-api -h hello-world-api.intranet.br \ --network network_public \ \ -v /storage/hello-world-api:/var/www/html:ro \ \ rtsp/lighttpdEdite o HOST que responde pelo domínio “exemplo.com.br” inteiro, menu “Hosts” -> “Proxy hosts” -> vá na linha do Host, no final da linha clique nos três pontinhos “…” e vá no “Edit“:
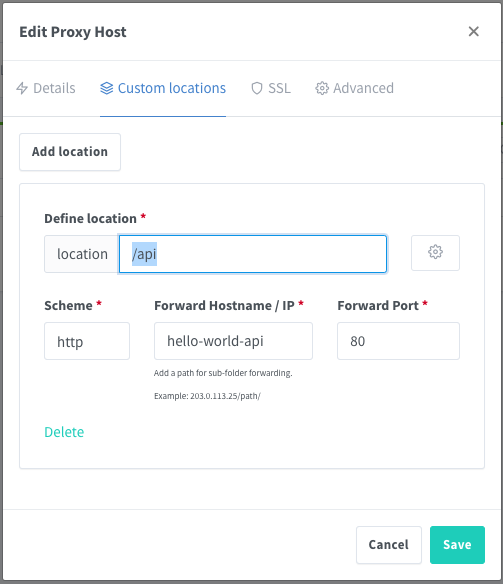
Vá na guia “Custom locations” e adicione uma localização em “Add location“, no exemplo abaixo, tudo que for para “/api” será enviado para o container “hello-world-api” porta 80. Você pode clicar várias vezes em “Add location” para adicionar mais redirecionamentos de pastas do seu domínio para um container específico:
Com isso aprendemos os principais recursos de proxy-reverso do NPM, navegue pelo software para aprender novos recursos como autenticação, lista de acessos, etc…
Eu recomendo que você evite os redirecionamentos de pastas “/api-client“, no lugar, prefira criar entradas de DNS como “api-client.exemplo.com.br” e entregar o nome inteiro para o container alvo. Isso facilita hospedar sub-domínios em locais diferentes sem um depender do outro no fluxo de conexões TCP/HTTP.
Pouca configuração é melhor que muita configuração!
Destrua tudo que foi construído nesse capítulo para praticar o próximo no mesmo ambiente:
Bash
# Remover NPM docker stop npm-app docker rm npm-app # Remover containers lighttpd docker rm -f hello-world-home docker rm -f hello-world-api6 – Traefik
O favorito de quem sobe muitos containers e não tem tempo a perder!
Embora o Traefik consiga fazer tudo que o NPM faz, ele é MUITO chato de configurar na mão, em contra-partida, você consegue subir todo serviço de maneira automática sem tocar no Traefik, tudo isso graças ao mapeamento de “labels” dos containers.
O Traefik pode ser conectar ao Docker e detectar novos containers que tenham os labels instruindo o redirecionamento desejado.
Rodando o Traefik:
Bash
# Criar container Traefik (básico) # Diretorio de dados persistentes mkdir -p /storage/traefik-app/letsencrypt # Remover container caso exista: docker rm -f traefik-app # Remover imagem atual para forçar download com imagem atualizada: docker rmi traefik:latest # Obter imagem (no momento, latest = v3.x): # - opcional, o comando docker run abaixo ja faz isso docker pull traefik:latest # Criar container: # - nome: traefik-app # - Colocar na rede network_public # - portas: # 80 = HTTP # 443 = HTTPs (HTTP+TLS) # - volume mapeado: # arquivo /var/run/docker.sock mapeado em /var/run/docker.sock no container # - argumento especial '--providers.docker' instrue o Traefik a consultar # o socket unix do Docker para obter suas configurações. # docker run \ -d --restart=unless-stopped \ \ --name traefik-app -h traefik-app.intranet.br \ --network network_public \ \ -p 80:80 \ -p 443:443 \ \ -v /var/run/docker.sock:/var/run/docker.sock:ro \ -v /storage/traefik-app/letsencrypt:/etc/letsencrypt \ \ traefik:latest \ --api=true \ --providers.docker=true \ --entrypoints.web.address=:80 \ --entrypoints.websecure.address=:443 \ --certificatesresolvers.letsencrypt.acme.httpchallenge=true \ --certificatesresolvers.letsencrypt.acme.httpchallenge.entrypoint=web \ --certificatesresolvers.letsencrypt.acme.email=seu-email@exemplo.com.br \ --certificatesresolvers.letsencrypt.acme.storage=/etc/letsencrypt/acme.jsonObserve que mapeamos o caminho do socket unix (/var/run/docker.sock) do Docker (HOST) no mesmo caminho dentro do container, em modo somente leitura (“:ro”). Isso dá ao Traefik acesso à configuração do Docker para consultar o JSON de todos os containers em execução.
O Traefik consultará todos os containers em busca de “labels” que o instrua como prover o encaminhamento de URLs.
Objetivamente: cada container “puxa” o trafego para si nesse tipo de ambiente.
Vamos criar dois containers de teste com manifesto de labels.
Primeiro container para a página inicial:
Bash
# Lighttpd para receber o site exemplo.com.br e www.exemplo.com.br # Criar a pasta no HOST: mkdir -p /storage/hello-world-home echo 'Ola, deu certo pelo Traefik' > /storage/hello-world-home/index.html # Rodar o container chamado hello-world-home # - Observe que não há porta mapeada, esse container é 100% privado # - Observe os labels do Traefik: docker run -d \ -d --restart=unless-stopped \ --name hello-world-home -h hello-world-home.intranet.br \ --network network_public \ \ -v /storage/hello-world-home:/var/www/html:ro \ \ --label "traefik.enable=true" \ --label "traefik.http.routers.exemplo.rule=Host(\`exemplo.com.br\`) || Host(\`www.exemplo.com.br\`)" \ --label "traefik.http.routers.exemplo.priority=100" \ --label "traefik.http.routers.exemplo.entrypoints=websecure" \ --label "traefik.http.routers.exemplo.tls=true" \ --label "traefik.http.routers.exemplo.tls.certresolver=letsencrypt" \ --label "traefik.http.services.exemplo.loadbalancer.server.port=80" \ \ rtsp/lighttpdSegundo container para a pasta “/api” para o site “exemplo.com.br” (e o “www” dele):
Bash
# Lighttpd para receber o site exemplo.com.br/api e api.exemplo.com.br # Criar a pasta no HOST: mkdir -p /storage/hello-world-api echo '{ "nome": "Patolino", "age": "6" }' > /storage/hello-world-api/index.json # Remover: docker rm -f hello-world-api # Rodar o container chamado hello-world-home # - Observe que não há porta mapeada, esse container é 100% privado docker run -d \ -d --restart=unless-stopped \ --name hello-world-api -h hello-world-api.intranet.br \ --network network_public \ \ -v /storage/hello-world-api:/var/www/html:ro \ \ --label "traefik.enable=true" \ --label "traefik.http.routers.api.rule=(Host(\`exemplo.com.br\`) || Host(\`www.exemplo.com.br\`)) && PathPrefix(\`/api\`)" \ --label "traefik.http.routers.api.priority=200" \ --label "traefik.http.routers.api.entrypoints=websecure" \ --label "traefik.http.routers.api.tls=true" \ --label "traefik.http.routers.api.tls.certresolver=letsencrypt" \ --label "traefik.http.services.api.loadbalancer.server.port=80" \ \ rtsp/lighttpdObserve o “priority“, quanto mais específica for seu filtro, aumente o valor de prioridade para que a regra seja processada primeiro em relação à configuração de outros containers.
O Traefik é assim mesmo, você roda ele de forma simples, e deixa o resto pra cada container declarar suas capturas. Trabalho 100% automático!
O ponto fraco do Traefik é que você tem que reconfigurar todos os seus containers para incluir as declarações de labels.
Ao declarar um novo container, o Traefik pode demorar entre 1 e 2 minutos para consultar a API remota do Let’s Encrypt para obter o certificado para ele. Garanta que o DNS foi configurado corretamente ANTES de criar o container, pois há o risco do excesso de tentativas sem sucesso resultar no bloqueio do seu IP na API do Let’s Encrypt.
Traefik personalizado na mão junto com o modo automático
Você pode rodar o Traefik especificando todas as configurações no CMD (command) do container, veja um exemplo bem completo e exaustivo:
Bash
# Criar container Traefik (completo) # - Diretorios mapeados: mkdir -p /storage/traefik-app/letsencrypt mkdir -p /storage/traefik-app/logs mkdir -p /storage/traefik-app/config # - Arquivo de configuracao manual touch /storage/traefik-app/config/traefik.yml # - Remover atual: docker rm -f traefik-app # - Rodar docker run \ -d --restart=unless-stopped \ \ --name traefik-app -h traefik-app.intranet.br \ --network network_public \ \ -p 80:80 \ -p 443:443 \ \ -v /var/run/docker.sock:/var/run/docker.sock:ro \ -v /storage/traefik-app/letsencrypt:/etc/letsencrypt \ -v /storage/traefik-app/config:/etc/traefik \ -v /storage/traefik-app/logs:/logs \ \ traefik:latest \ \ --global.checkNewVersion=false \ --global.sendAnonymousUsage=false \ \ --api.dashboard=true \ --api.insecure=true \ \ --log.level=INFO \ --log.filePath=/logs/error.log \ \ --accessLog.filePath=/logs/access.log \ \ --entrypoints.web.address=:80 \ --entrypoints.web.http.redirections.entryPoint.to=websecure \ --entrypoints.web.http.redirections.entryPoint.scheme=https \ --entrypoints.web.http.redirections.entryPoint.permanent=true \ \ --entrypoints.websecure.address=:443 \ \ --providers.docker=true \ --providers.file.directory=/etc/traefik \ \ --certificatesresolvers.letsencrypt.acme.email=seu-email@exemplo.com.br \ --certificatesresolvers.letsencrypt.acme.storage=/etc/letsencrypt/acme.json \ --certificatesresolvers.letsencrypt.acme.httpchallenge.entrypoint=webNo exemplo acima, implementamos:
- Logs: vão ficar armazenados no HOST no diretório /storage/traefik-app/logs, tome cuidado com o crescimento e armazenamento deles em obediência ao Marco Civil;
- Configuração personalizada: arquivos .yml (formato YAML) podem ser criados e configurados no HOST no diretório /storage/traefik-app/config com as personalizações manuais do seu ambiente;
Com o uso de Docker Compose, você não precisará se preocupar com a quantidade de argumentos do container, já que um único arquivo de stack resolverá todas as suas necessidades.
Outra forma de resolver é transformar a configuração em parte dos dados persistentes do container, convertendo a configuração de argumentos do Traefik em um arquivo de configuração. Esse método permite que você edite o arquivo sem reiniciar o container pois o Traefik monitora alterações em tempo real. O único defeito é que se você errar a configuração o Traefik bug ao vivo!
Arquivo de configuração no HOST em /storage/traefik-app/config/traefik.yml:
YAML
global: checkNewVersion: false sendAnonymousUsage: false api: dashboard: true insecure: true log: level: INFO filePath: /logs/error.log accessLog: filePath: /logs/access.log entryPoints: web: address: ":80" websecure: address: ":443" certificatesResolvers: letsencrypt: acme: email: seu-email@exemplo.com.br storage: /etc/letsencrypt/acme.json httpChallenge: entryPoint: web providers: docker: endpoint: "unix:///var/run/docker.sock" exposedByDefault: false file: directory: "/etc/traefik/config" watch: trueRodando o container Traefik usando o arquivo acima:
Bash
# Criar container Traefik (completo) # - Diretorios mapeados: mkdir -p /storage/traefik-app/letsencrypt mkdir -p /storage/traefik-app/logs mkdir -p /storage/traefik-app/config # - Arquivo de configuracao manual touch /storage/traefik-app/config/traefik.yml # - Remover atual: docker rm -f traefik-app # - Rodar docker run \ -d --restart=unless-stopped \ \ --name traefik-app -h traefik-app.intranet.br \ --network network_public \ \ -p 80:80 \ -p 443:443 \ -p 8080:8080 \ \ -v /var/run/docker.sock:/var/run/docker.sock:ro \ -v /storage/traefik-app/letsencrypt:/etc/letsencrypt \ -v /storage/traefik-app/config:/etc/traefik \ \ traefik:latest \ --configFile=/etc/traefik/traefik.ymlCom isso encerramos os principais exemplos de uso do Traefik!
Apagar Traefik:
Bash
# Remover Traefik (traefik-app) docker stop traefik-app docker rm traefik-app7 – Caddy
O Caddy segue a mesma ideia do Traefik de ser “zero-touch” e prover redirecionamentos automáticos por meio de labels mas também permitindo personalizações manuais.
Ele parece simples, mas é mais esquisito de configurar que o Traefik, logo ele não se encaixará em todas as soluções. Sua configuração é escrita em blocos e os labels são mais curtos.
O Caddy também faz a obtenção automática de certificados assinados usando ACME-Let’sEncrypt.
Rodando Caddy:
Bash
# Criar container Traefik (básico) # Diretorio de dados persistentes mkdir -p /storage/caddy-app mkdir -p /storage/caddy-app/config mkdir -p /storage/caddy-app/logs mkdir -p /storage/caddy-app/data # Remover container caso exista: docker rm -f caddy-app # Remover imagem atual para forçar download com imagem atualizada: docker rmi lucaslorentz/caddy-docker-proxy:latest # Obter imagem (no momento, latest = v2.9.x): # - opcional, o comando docker run abaixo ja faz isso docker pull lucaslorentz/caddy-docker-proxy:latest # Criar container: # - nome: caddy-app # - Colocar na rede network_public # - portas: # 80 = HTTP # 443 = HTTPs (HTTP+TLS) # - volumes mapeados: # arquivo /var/run/docker.sock mapeado em /var/run/docker.sock no container # diretorios de config e logs do host mapeados dentro do container # docker run \ -d --restart=unless-stopped \ \ --name caddy-app -h caddy-app.intranet.br \ --network network_public \ \ -p 80:80 \ -p 443:443 \ \ -e CADDY_INGRESS_NETWORKS=network_public \ \ -v /var/run/docker.sock:/var/run/docker.sock:ro \ -v /storage/caddy-app/data:/data \ -v /storage/caddy-app/logs:/logs \ \ lucaslorentz/caddy-docker-proxy:latestCriando um container para puxar automaticamente uma URL pelo Caddy:
Bash
# Lighttpd para receber o site exemplo.com.br e www.exemplo.com.br # Criar a pasta no HOST: mkdir -p /storage/hello-world-home echo 'Ola, deu certo pelo Caddy' > /storage/hello-world-home/index.html # Remover container hello-world-home anterior: docker rm -f hello-world-home # Rodar o container chamado hello-world-home # - Observe que não há porta mapeada, esse container é 100% privado # - Observe os labels do Caddy: docker run -d \ -d --restart=unless-stopped \ --name hello-world-home -h hello-world-home.intranet.br \ --network network_public \ \ -v /storage/hello-world-home:/var/www/html:ro \ \ --label caddy=example.com \ --label caddy.reverse_proxy=http://hello-world-home:80 \ \ rtsp/lighttpdEmbora pareça simples e mágico, o Caddy tem suas limitações, o Traefik e o NPM ainda são superiores.
Conclusão
Recomendo focar no Traefik, ele roda sem toque, 100% invisível, suporta todos os recurso de automatização e segurança e deixa com que o serviços (containers) assumam seus nomes e diretórios HTTP para escuta.
Até a próxima!
Patrick Brandão, patrickbrandao@gmail.com








 English (US) ·
English (US) ·  Portuguese (BR) ·
Portuguese (BR) · 